
Cloud computing certainly has a lot of perks. From scalability, through cost-effectiveness (when done right), flexibility, scalability and much more. However, these great benefits might come at the price of service reliability.
Service reliability issues are the various types of failures that may affect the success of a cloud service.
Below are some of the causes:
- Computing resources missing
- Timeouts
- Network failure
- Hardware failure
But above all, the primary cause of service reliability issues is change.
Changes in the cloud encompass various advantages including new capabilities, features, security and reliability enhancements and more.
These changes are also subject to setbacks such as regression, downtime and bugs.
Much like in our everyday lives, change is inevitable. Change signifies cloud platforms such as Azure are evolving and improving in performance, so we can’t afford to ignore change, rather we need to expect it and plan for it.
Microsoft strives to make updates as transparent as possible and deploy changes safely.
In this post, we will look at the safe deployment practices they implement to make sure you, the customer, is not affected by the setbacks caused by such changes.
How Azure deploys changes safely
How does Azure deploy their releases / changes / updates?
Azure assumes upfront there is an unknown problem that would arise as a result of the change being deployed. They therefore plan in a way that enables the discovery of the problem and automate mitigation actions for when the problem arises. Even the slightest of change can pose a risk to the stability of the system.
Since we’ve already agreed that change is inevitable, how can they prevent or minimize the impact of change?
- By ensuring the changes meet the quality standard before deployment. This can be achieved through test and integration validations.
- After the quality check, Azure gradually rolls out the changes or updates to detect any unexpected impact that was not foreseen during testing.
The gradual deployment gives Azure an opportunity to detect any issues on a smaller scale before the change is deployed on a broad production level and causes a larger impact on the system.
Both code and configuration changes go through a life cycle of stages where health metrics are monitored and automatic actions are triggered when any anomalies are detected.
These stages reduce any negative impact on the customers’ workloads associated with the software updates.
Canary regions / Early Updates Access Program
An Azure region is an area within a geography, containing one or more data centres.
Canary regions are just like any other Azure regions.
One of the canary regions is built with availability zones and the other without. Both regions are then paired to form a “paired region” to validate the data replication capabilities.
Several parties are invited to the program, from first-party services like Databricks, third-party services (from the azure marketplace) like Barracuda WAF-as-a-service to a small set of external customers.
All these diverse parties are invited to cover all possible scenarios.
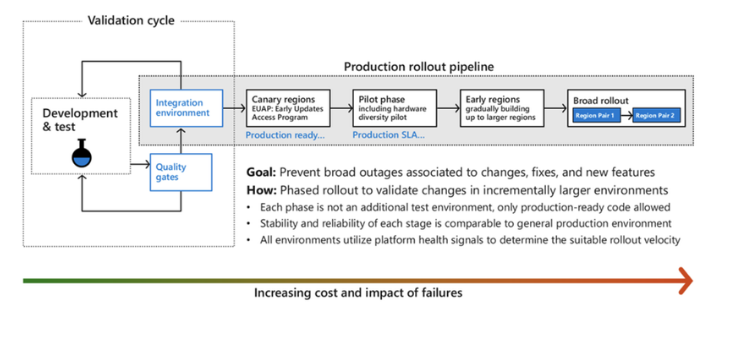 These canary regions are run through tests and end-to-end validation, to practice the detection and recovery workflows that would be run if any anomalies occur in real life. Periodic fault injections or disaster recovery drills are carried out at the region or Availability Zone Level, aimed to ensure the software update is of the highest quality before the change rolls out to broad customers and into their workloads.
These canary regions are run through tests and end-to-end validation, to practice the detection and recovery workflows that would be run if any anomalies occur in real life. Periodic fault injections or disaster recovery drills are carried out at the region or Availability Zone Level, aimed to ensure the software update is of the highest quality before the change rolls out to broad customers and into their workloads.
Pilot phase
Once the results from canary indicate that there are no known issues detected, deployment to production phase begins. Starting off with the pilot phase.
This phase enables Azure to try out the changes, still on a relatively small scale, but with more diversity of hardware and configurations.
This phase is especially important for software like core storage services and core compute infrastructure services, that have hardware dependencies.
For example, Azure offers servers with GPUs, large memory servers, commodity servers, multiple generations and types of processors, Infiniband, and more, so this enables flighting the changes and may enable detection of issues that would not surface during the smaller scale testing.
In each step along the way, thorough health monitoring and extended ‘bake times’ enable potential failure patterns to surface, and increase confidence in the changes while greatly reducing the overall risk to customers.
Once it’s determined that the results from the pilot phase are good, deployment of the changes progresses to more regions gradually. changes deploy only as long as no negative signals surface.
The deployment system attempts to deploy a change to only one availability zone within a region and due to region pairing, a change is first deployed to a region then its pair.
Safe deployment practices in action
Given the scale of Azure, it has more global regions than any other cloud provider, the entire rollout process is completely automated and driven by policy.
These policies include mandatory health signals for monitoring the quality of software. This shows that the same policies and processes determine how quickly software can be rolled out.
These policies also include mandatory ‘bake times’ between the stages outlined above.
Why the mandatory ‘bake times’?
The reason to have software sitting and baking for different periods of time across each phase is to make sure to expose the change to a full spectrum of load on that service.
For example, diverse organisational users might be coming online in the morning, gaming customers might be coming online in the evening, and new virtual machines (VMs) or resource creations from customers may occur over an extended period of time.
Below are some instances of safe deployment practices in action:
- Global services, which cannot take the approach of progressively deploying to different clusters, regions, or service rings, also practice a version of progressive rollouts in alignment with SDP.
These services follow the model of updating their service instances in multiple phases, progressively deviating traffic to the updated instances through Azure Traffic Manager.
If the signals are positive, more traffic gets deviated over time to updated instances, increasing confidence and unblocking the deployment from being applied to more service instances over time.
- the Azure platform also has the ability to deploy a change simultaneously to all of Azure instead of the gradual deployment.
Although the safe deployment policy is mandatory, Azure can choose to accelerate it when certain emergency conditions are met.
For example, for a fix where the risk of regression is overcome by the fix mitigating a problem that’s already very impactful on customers.
Conclusion
As we earlier said, change is inevitable. The agility and continual improvement of cloud services is one of the key value propositions of the cloud. Rather than trying to avoid change we should plan for it, by implementing safe deployment practices and mitigating negative impact.
We recommend keeping up to date with the latest releases, product updates, and the roadmap of innovations, and if you need help to better plan and rollout your architecture to control impact of change on your own cloud environment, we’re a click away.